Diabetes Prediction Model
🎯 Project Overview
This comprehensive machine learning project develops a predictive model for diabetes detection using health metrics from 100,000 patient records. Early diabetes detection is crucial for effective management and prevention of complications, making this model a valuable tool for healthcare applications.
📊 Dataset Information
Size: 100,000 patient records
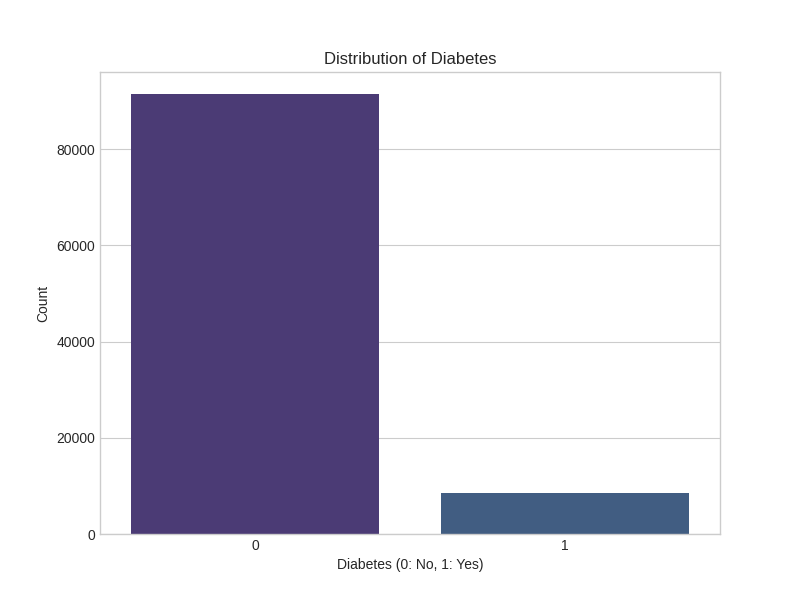
Target: Binary classification (Diabetic/Non-diabetic)
Key Features
- Demographics: Gender, Age
- Health Conditions: Hypertension, Heart Disease
- Lifestyle: Smoking History
- Physical Metrics: BMI (Body Mass Index)
- Medical Indicators: HbA1c Level, Blood Glucose Level
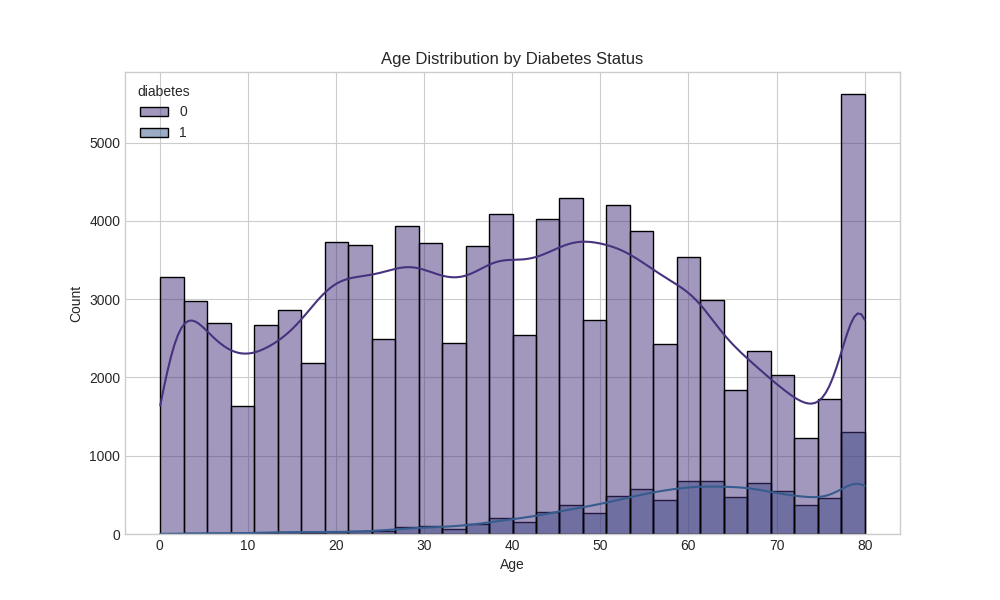
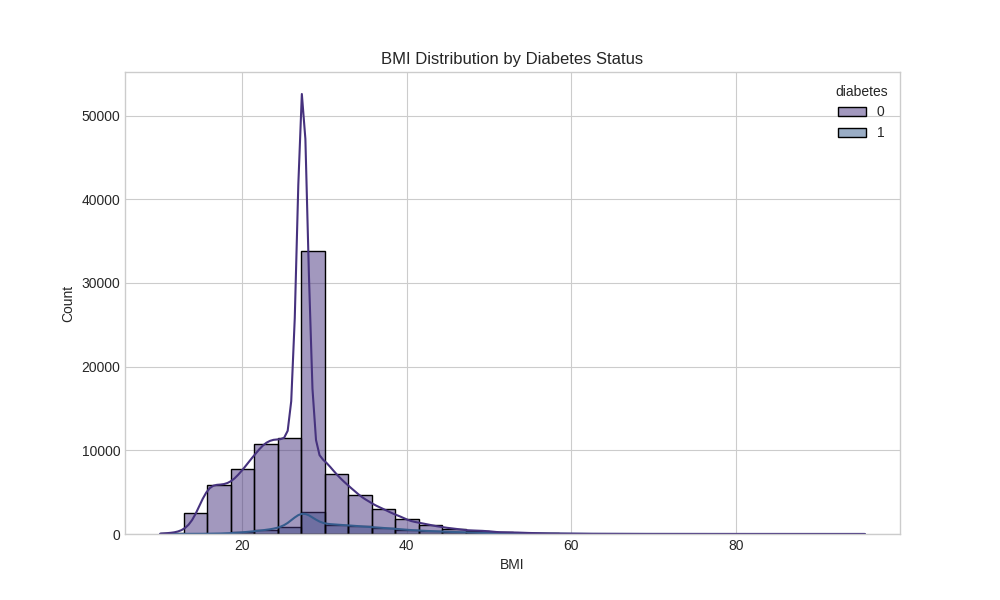
🔬 Exploratory Data Analysis
Data Distribution Analysis
The project includes comprehensive exploratory data analysis with detailed visualizations:
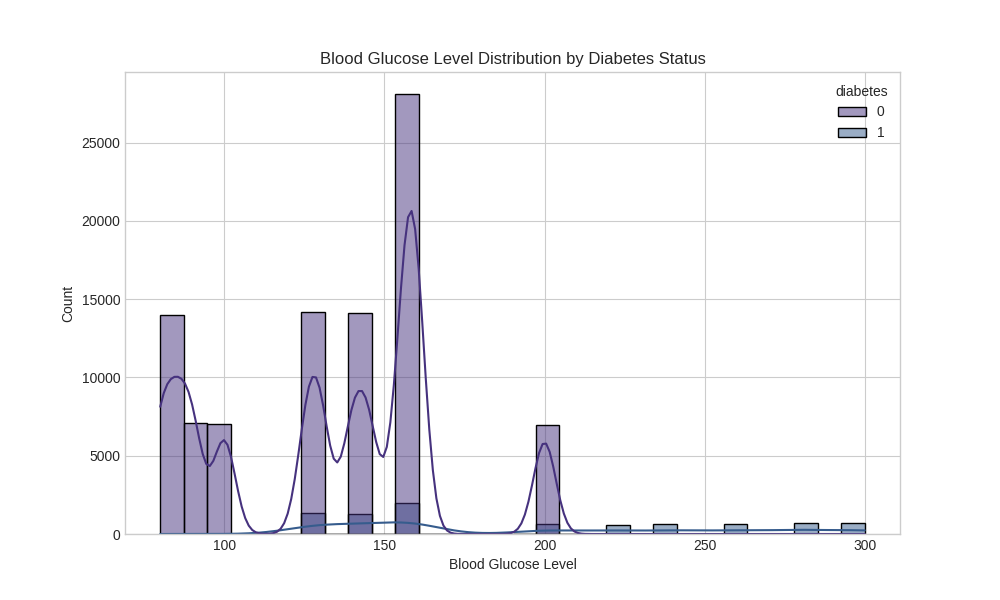
Key Health Indicators
Blood Glucose Level Distribution:
HbA1c Level Analysis:
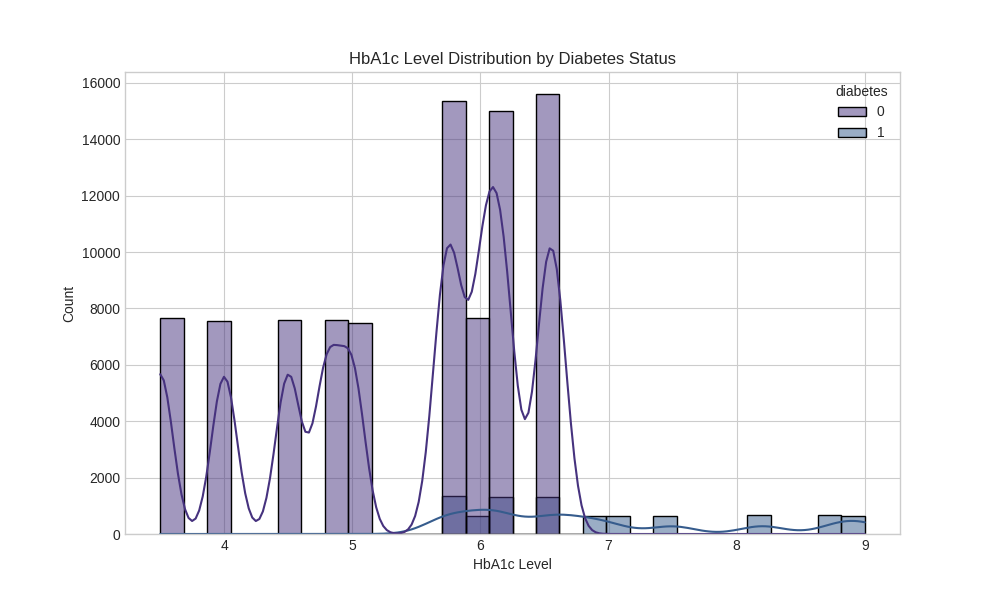
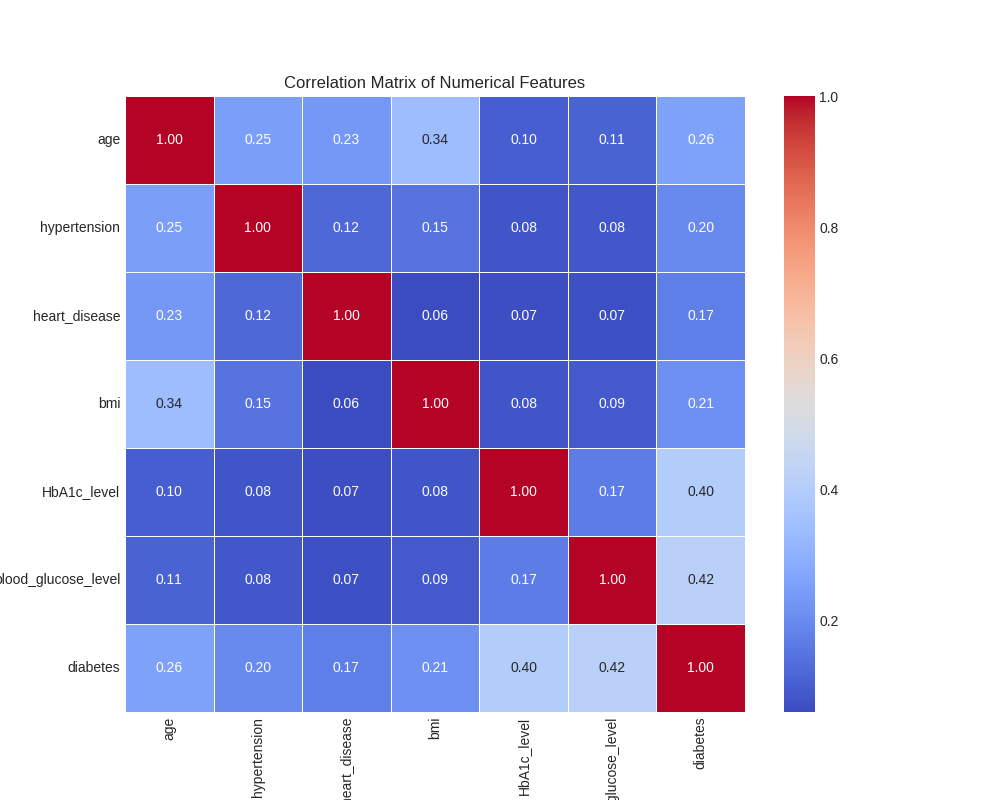
Correlation Analysis
Understanding the relationships between different health metrics:
🔍 Feature Relationships
Diabetes by Demographics
Gender Analysis:
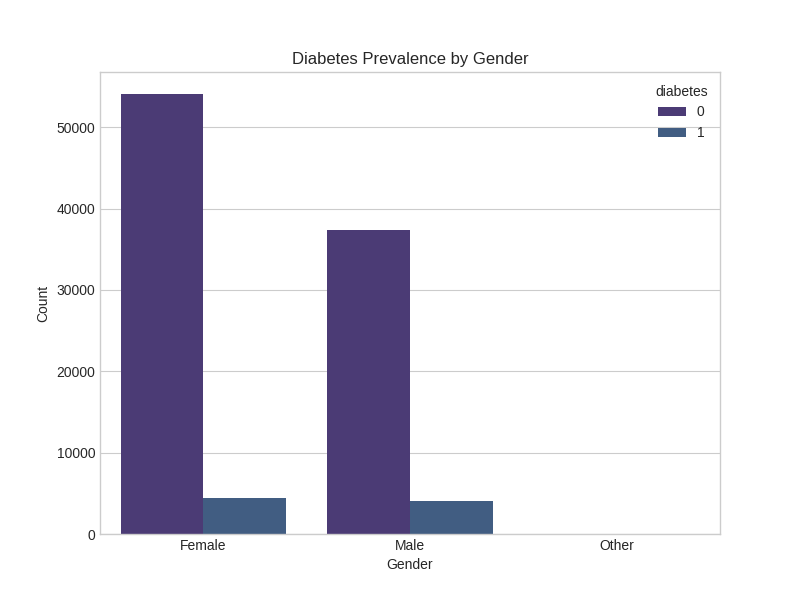
Hypertension Impact:
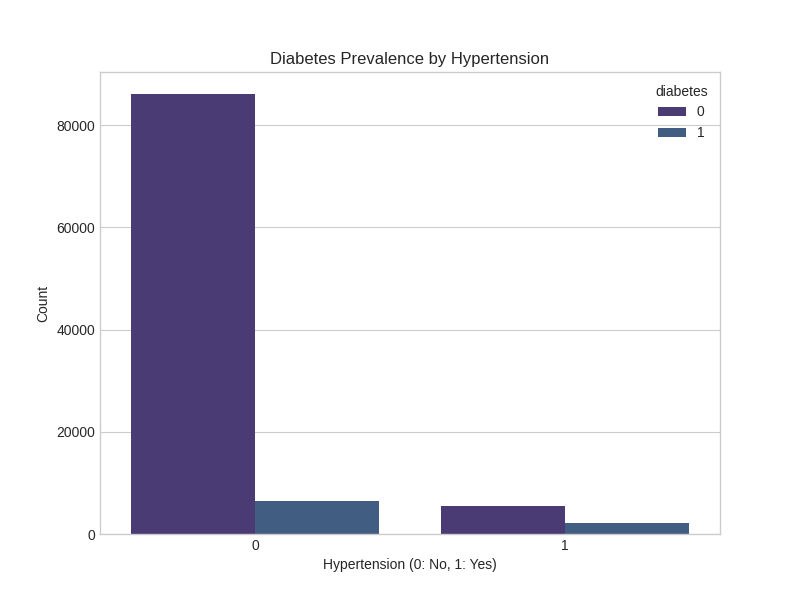
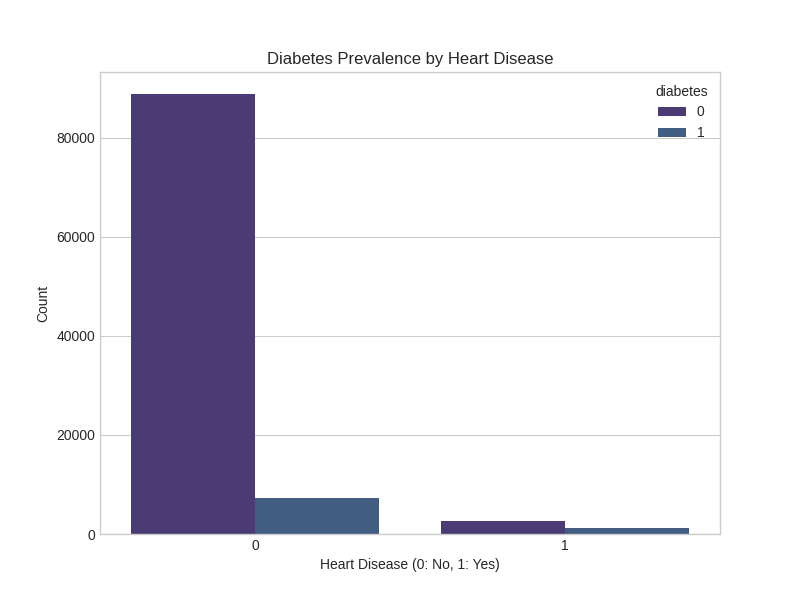
Heart Disease Correlation:
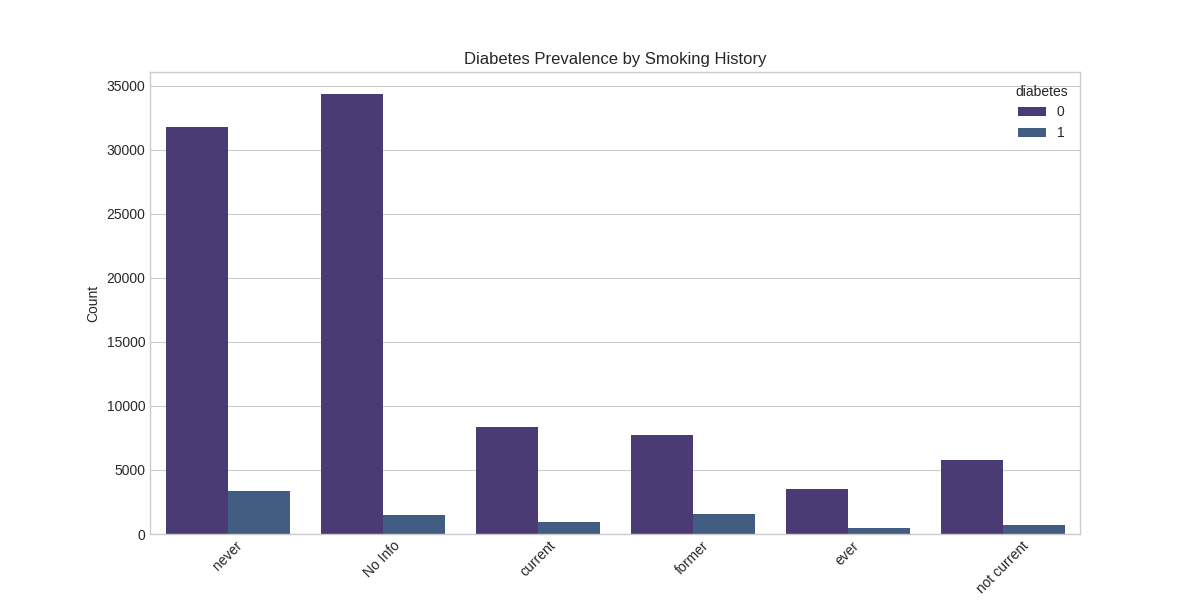
Smoking History Analysis:
🤖 Machine Learning Models
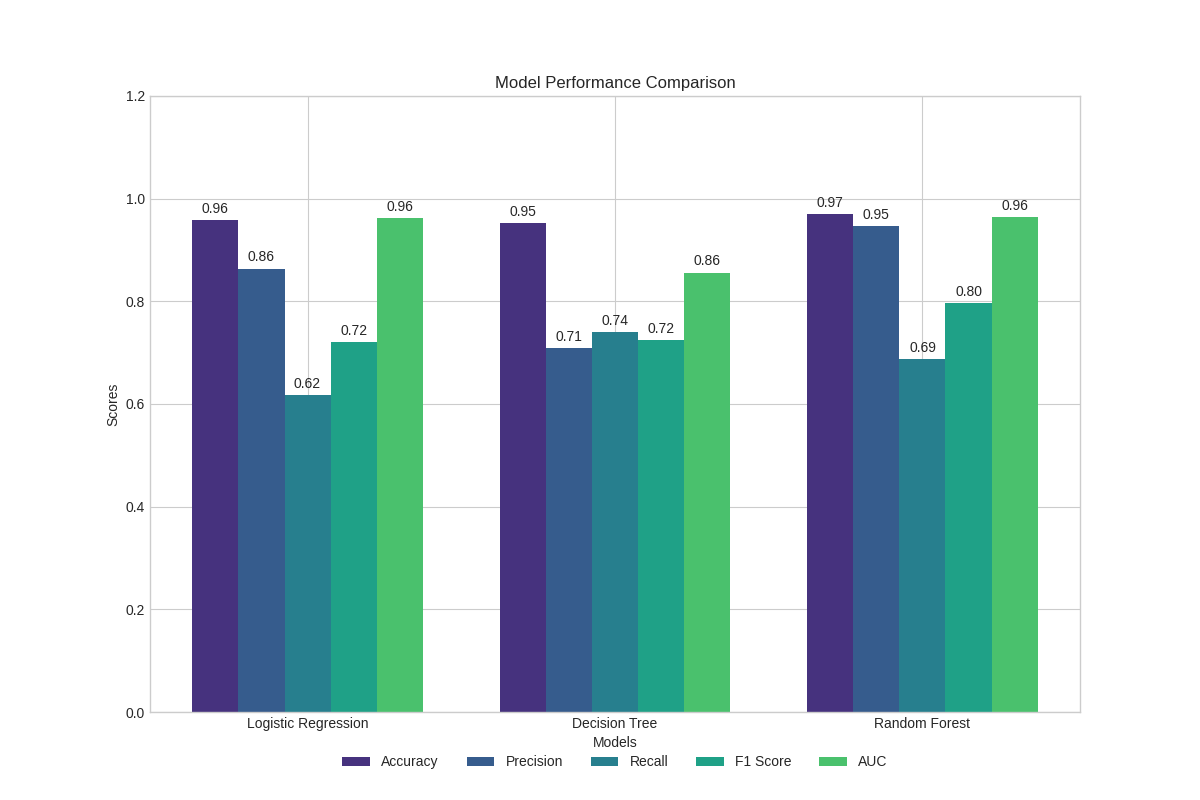
Model Comparison
The project implements multiple algorithms with comprehensive evaluation:
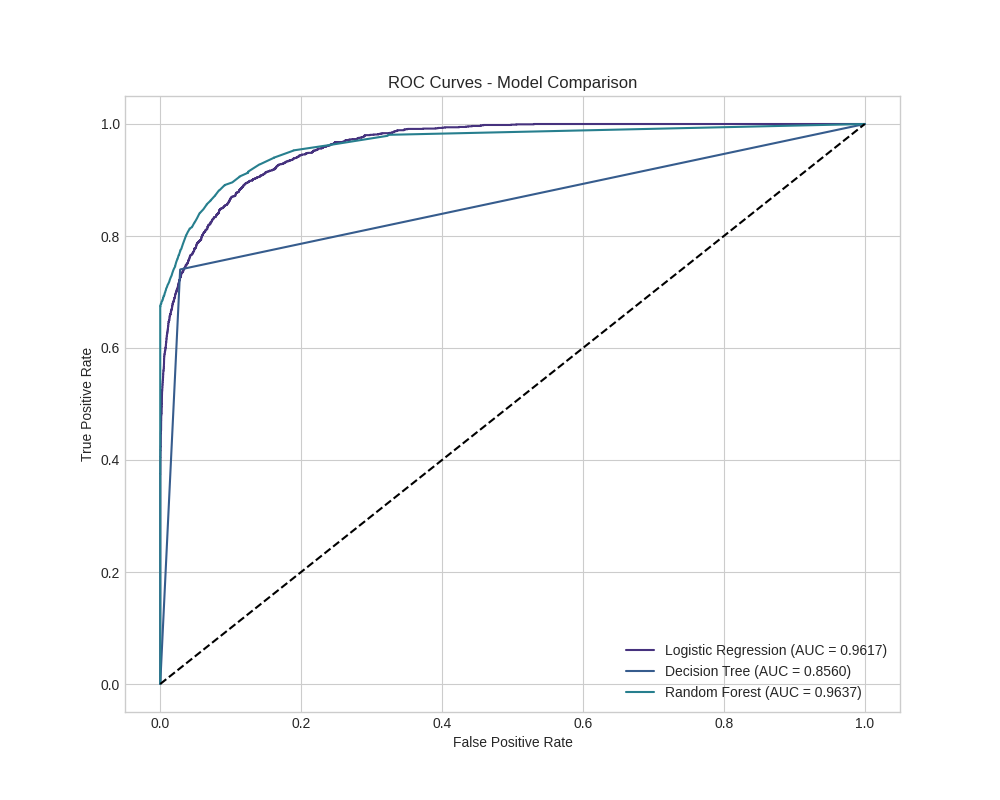
ROC Curve Analysis
Overall Model Performance:
Individual Model Performance
Logistic Regression:
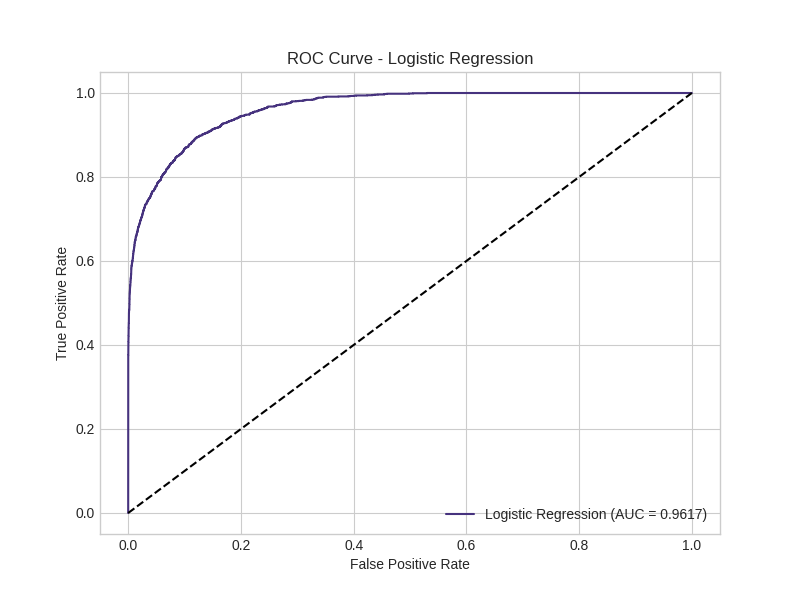

Decision Tree:
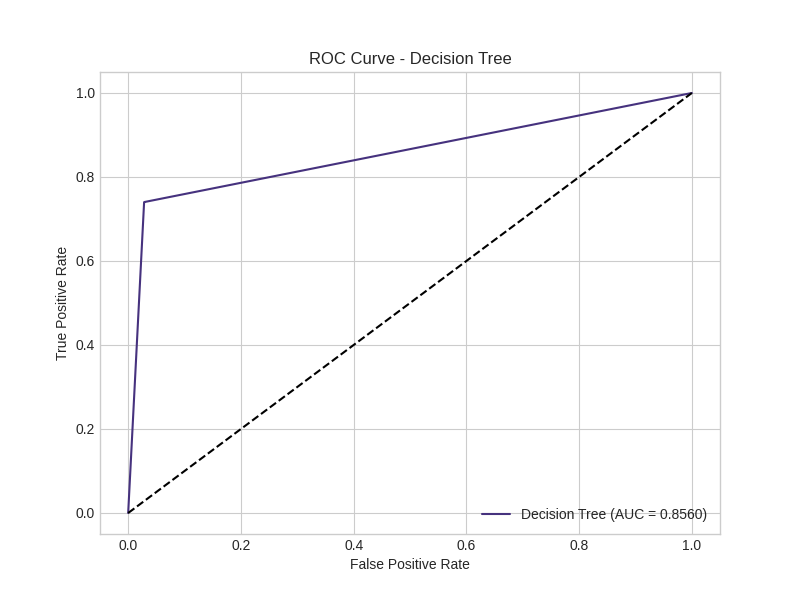
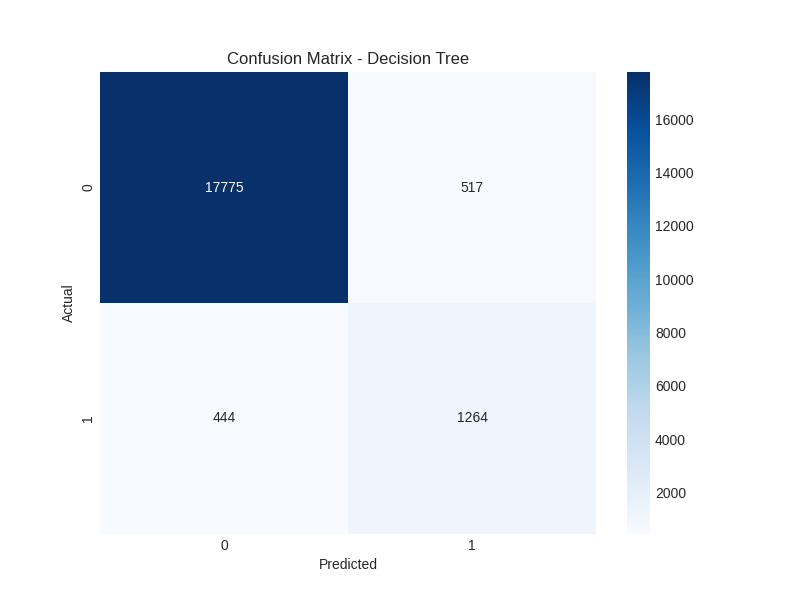
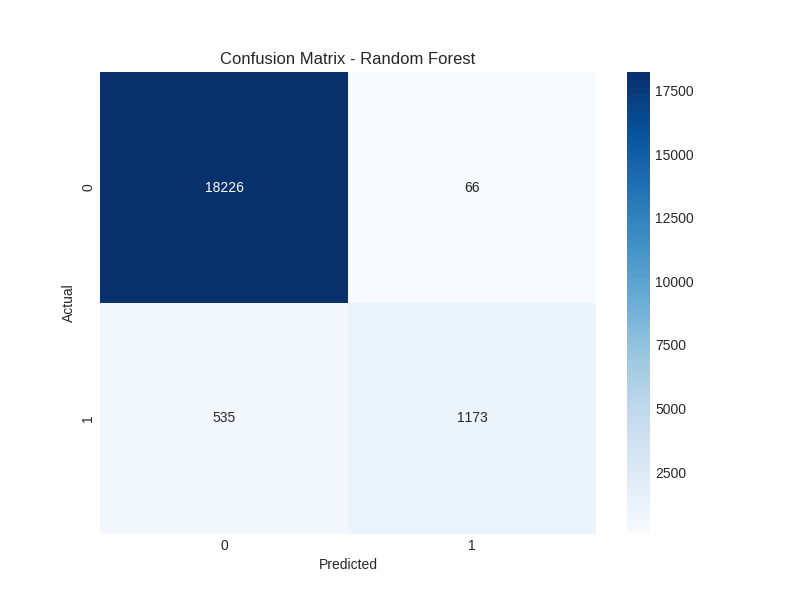
Random Forest:
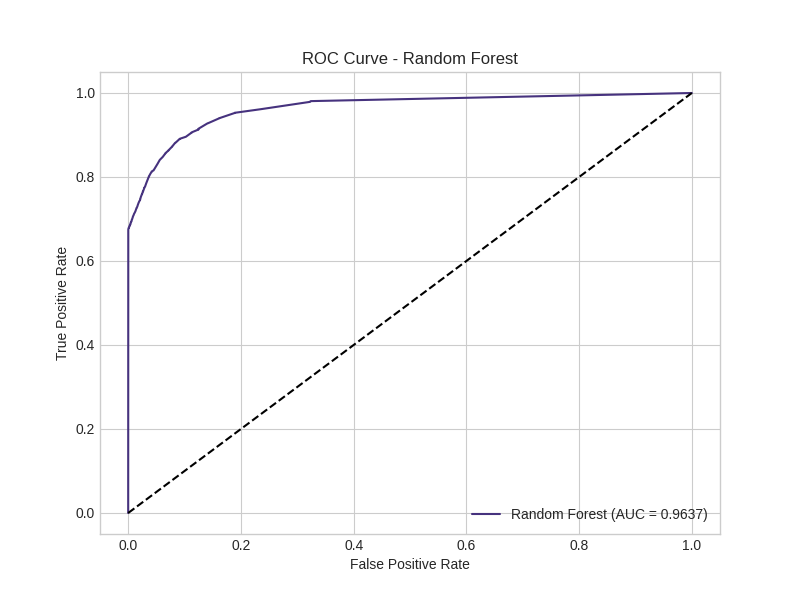
🎯 Feature Importance
Understanding which factors contribute most to diabetes prediction:
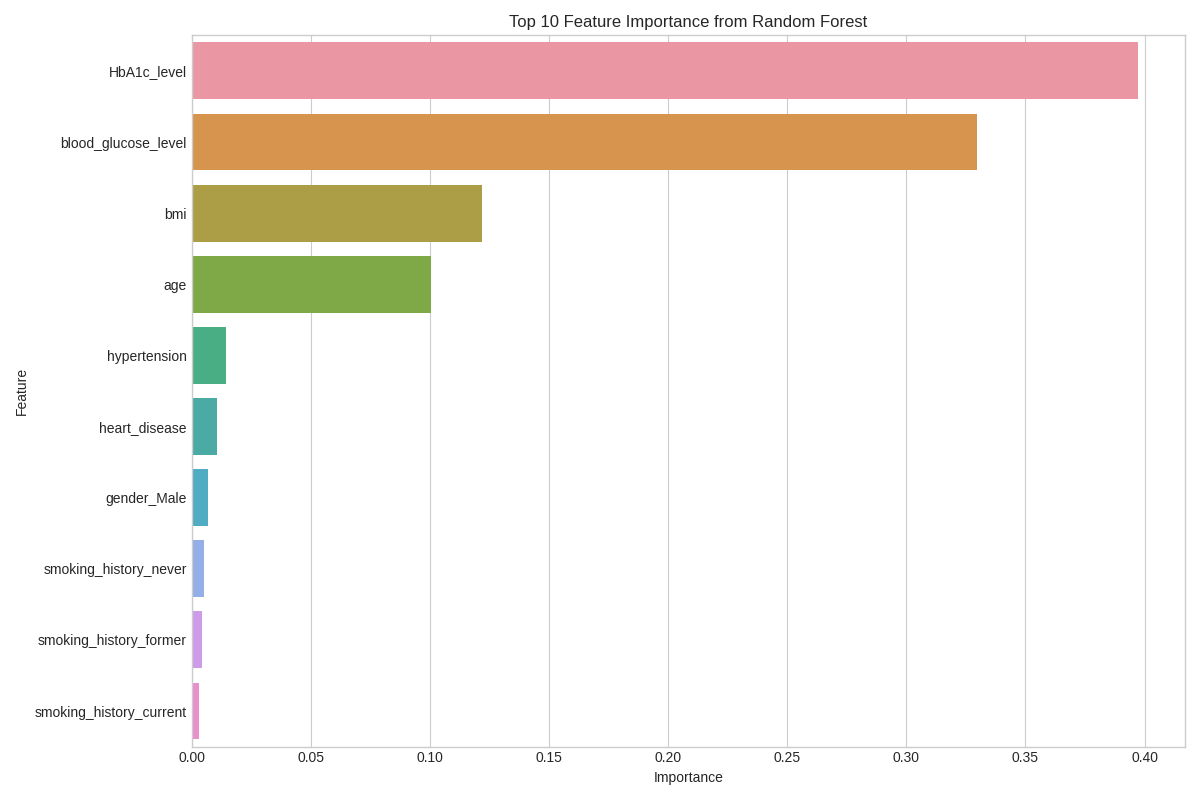
The model identified the most significant predictors:
- Blood Glucose Level - Primary diabetes indicator
- HbA1c Level - Average blood sugar measure
- Age - Diabetes risk increases with age
- BMI - Weight-related diabetes risk factor
📈 Model Performance
Key Results
- Best Model: Tuned Random Forest
- Accuracy: ~97.10% on test set
- Clinical Relevance: Model predictions align with established medical knowledge
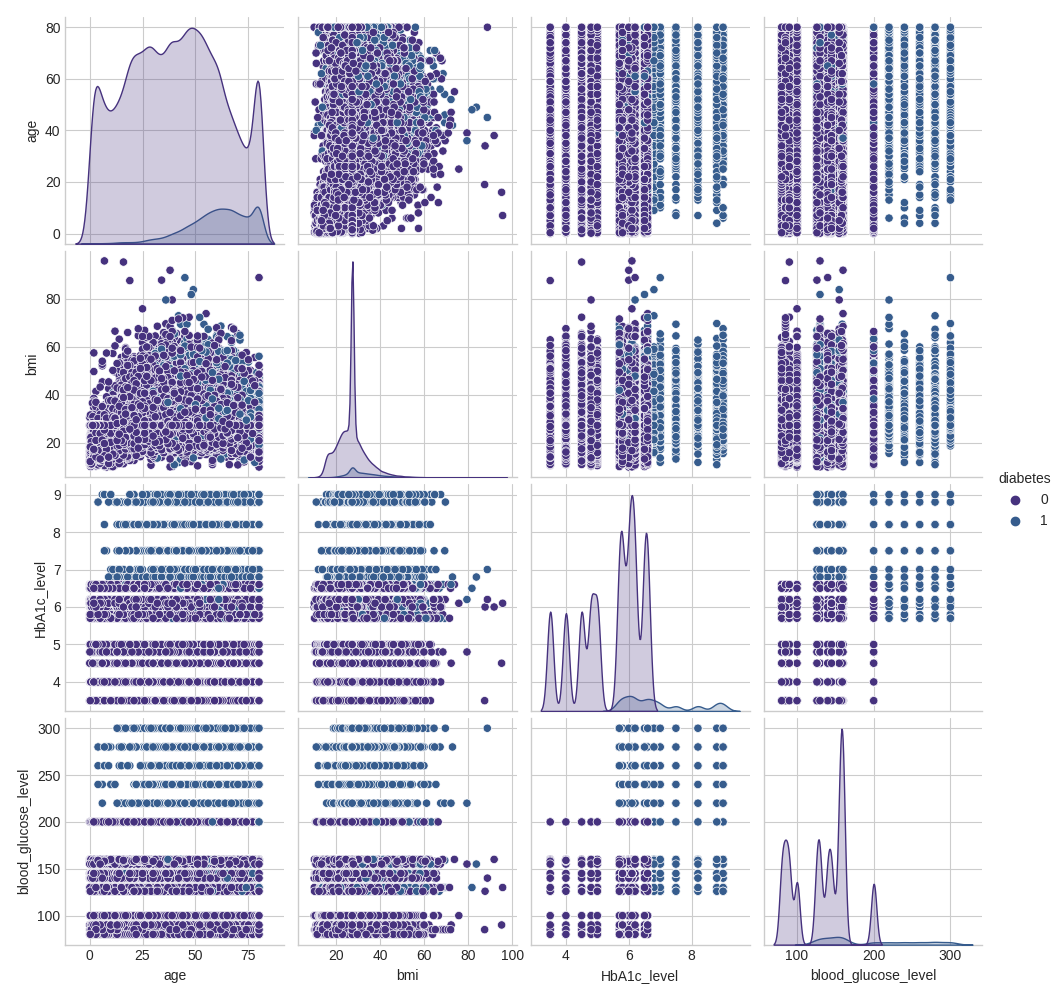
Comprehensive Data Exploration
The project includes detailed pairwise analysis of features:
💻 Implementation & Usage
Project Structure
diabetes_prediction_project/
├── data/ # Dataset files
├── notebooks/ # Jupyter analysis notebooks
├── src/ # Model files and prediction scripts
├── images/ # Generated visualizations
└── README.md # Project documentation
Prediction Interface
- Programmatic API: Python function for integration
- Command-line Tool: CLI for direct predictions
- Model Artifacts: Saved model and scaler for deployment
Example Usage
patient_data = {
'gender': 'Male',
'age': 45.0,
'hypertension': 0,
'heart_disease': 0,
'smoking_history': 'never',
'bmi': 28.5,
'HbA1c_level': 6.8,
'blood_glucose_level': 140
}
prediction, probability = predict_diabetes(patient_data)🏥 Clinical Impact
Medical Significance
- Early Detection: Enables proactive diabetes management
- Risk Assessment: Identifies high-risk individuals
- Resource Optimization: Efficient healthcare resource allocation
- Preventive Care: Supports lifestyle intervention strategies
Practical Applications
- Clinical Decision Support: Integration into healthcare systems
- Population Screening: Large-scale diabetes risk assessment
- Telemedicine: Remote patient monitoring and evaluation
- Health Education: Risk awareness and prevention programs
🚀 Technical Highlights
- Large-scale Dataset: 100,000 patient records processing
- Model Optimization: Systematic hyperparameter tuning
- Production-ready Code: Deployable prediction interface
- Comprehensive Evaluation: Multiple performance metrics
- Clinical Validation: Medically relevant feature importance
📋 Future Enhancements
- Advanced Algorithms: XGBoost, LightGBM, Neural Networks
- Model Explainability: SHAP and LIME integration
- Web Application: User-friendly prediction interface
- API Development: RESTful service for system integration
- Continuous Learning: Model updates with new data
🛠️ Technologies Used
- Python: Primary programming language
- Scikit-learn: Machine learning framework
- Pandas/NumPy: Data manipulation and analysis
- Matplotlib/Seaborn: Data visualization
- Jupyter: Interactive development environment